자료구조
자료구조란?
자료구조는 데이터 값들의 모임이다. 데이터는 여러 구조의 형태로 존재하는데, 어떤 자료구조를 사용하느냐에 따라 메모리의 효율성, 소프트웨어의 속도, 소프트웨어의 안정성이 달라진다. 상황에 따라 적절한 자료구조를 선택하여 사용해야 데이터를 체계적으로 저장하고 효율적으로 활용할 수 있다.
자료구조의 종류
자료구조는 단순 구조, 선형 구조, 비선형 구조로 나누어 볼 수 있다.
단순 구조는 정수, 실수, 문자열, boolean 등의 자료형을 말하는 것이다.
선형구조는 데이터를 순차적으로 나열시킨 형태로, 한 원소 뒤에 하나의 원소 만이 존재하는 형태이다. 여기에는 배열, 연결리스트, 스택, 큐 등이 있다.
비선형구조는 원소 간 다대다 관계를 가지는 구조이다. 여기에는 트리, 그래프 등이 있다.
배열
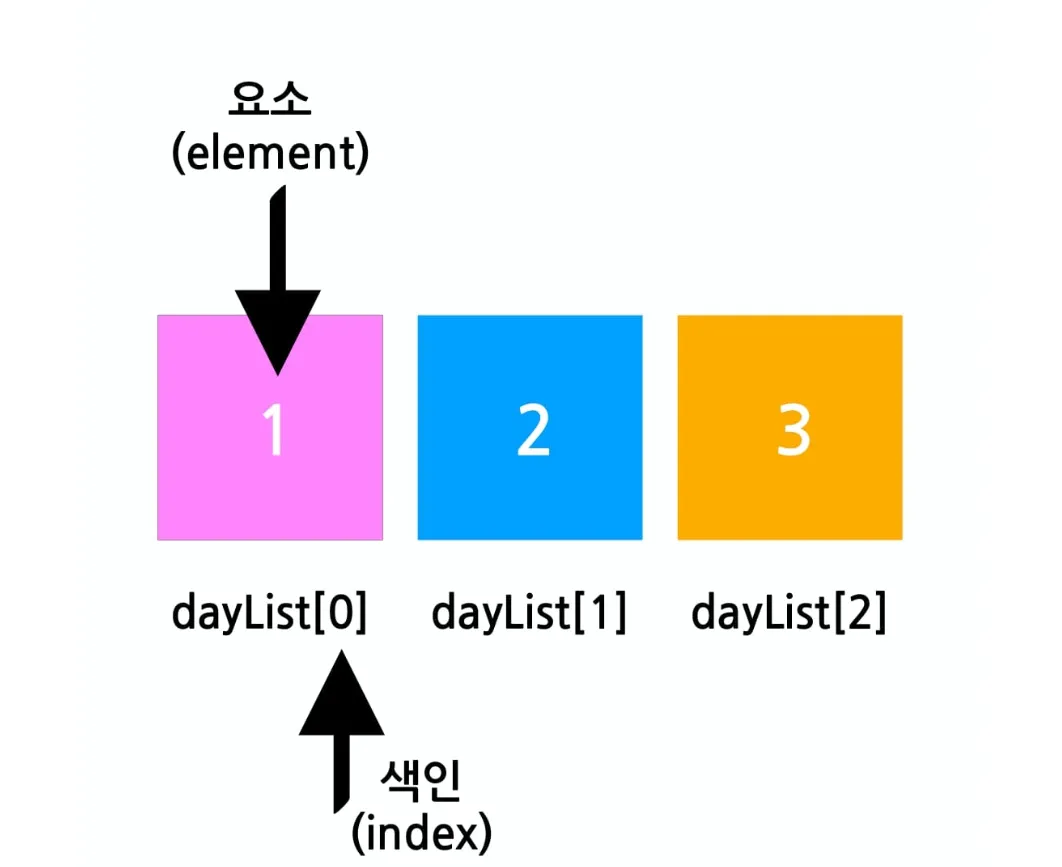
배열은 같은 종류의 데이터를 순서대로 저장한 자료구조이다. 배열에서의 각각의 값을 요소(element)라고 하며 그 순서대로 붙은 번호를 색인(index)라고 한다. 인덱스는 0부터 시작한다. 배열은 출석부에 비유할 수 있다.
배열은 인덱스를 이용하여 O(1)의 시간복잡도로 그 요소를 찾을 수 있다는 장점이 있지만, 고정된 크기를 가지기 때문에 추가하고 삭제하는 작업에 시간이 오래걸리며 배열 내 데이터 이동 및 재구성이 어렵다는 단점이 있다.
연결리스트
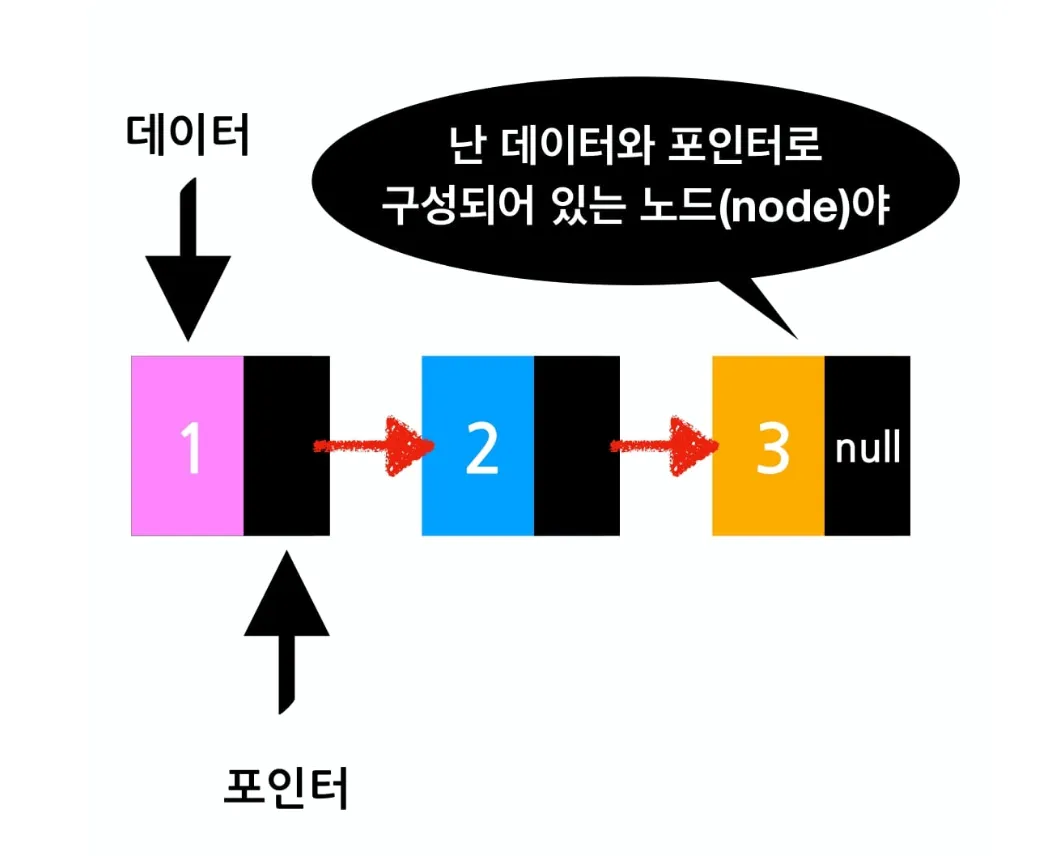
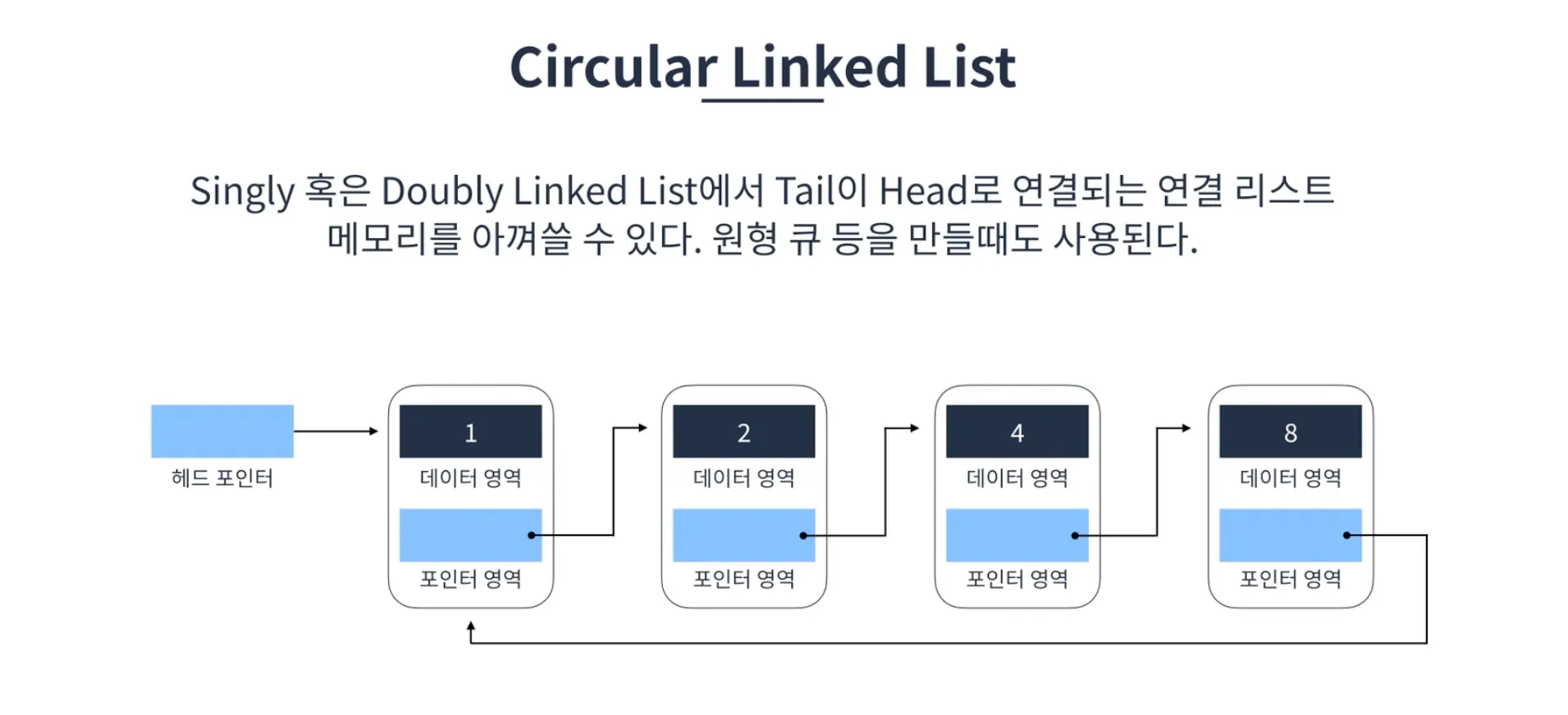
추가와 삭제가 반복되는 로직에는 배열을 사용 시 시간복잡도가 크다. 이러한 경우 사용할 수 있는 것이 연결리스트이다. 연결리스트는 각 요소를 포인터로 연결하여 관리하는 선형 자료구조이다. 각 요소는 노드라고 부르며 데이터 영역과 포인터 영역으로 구성된다.
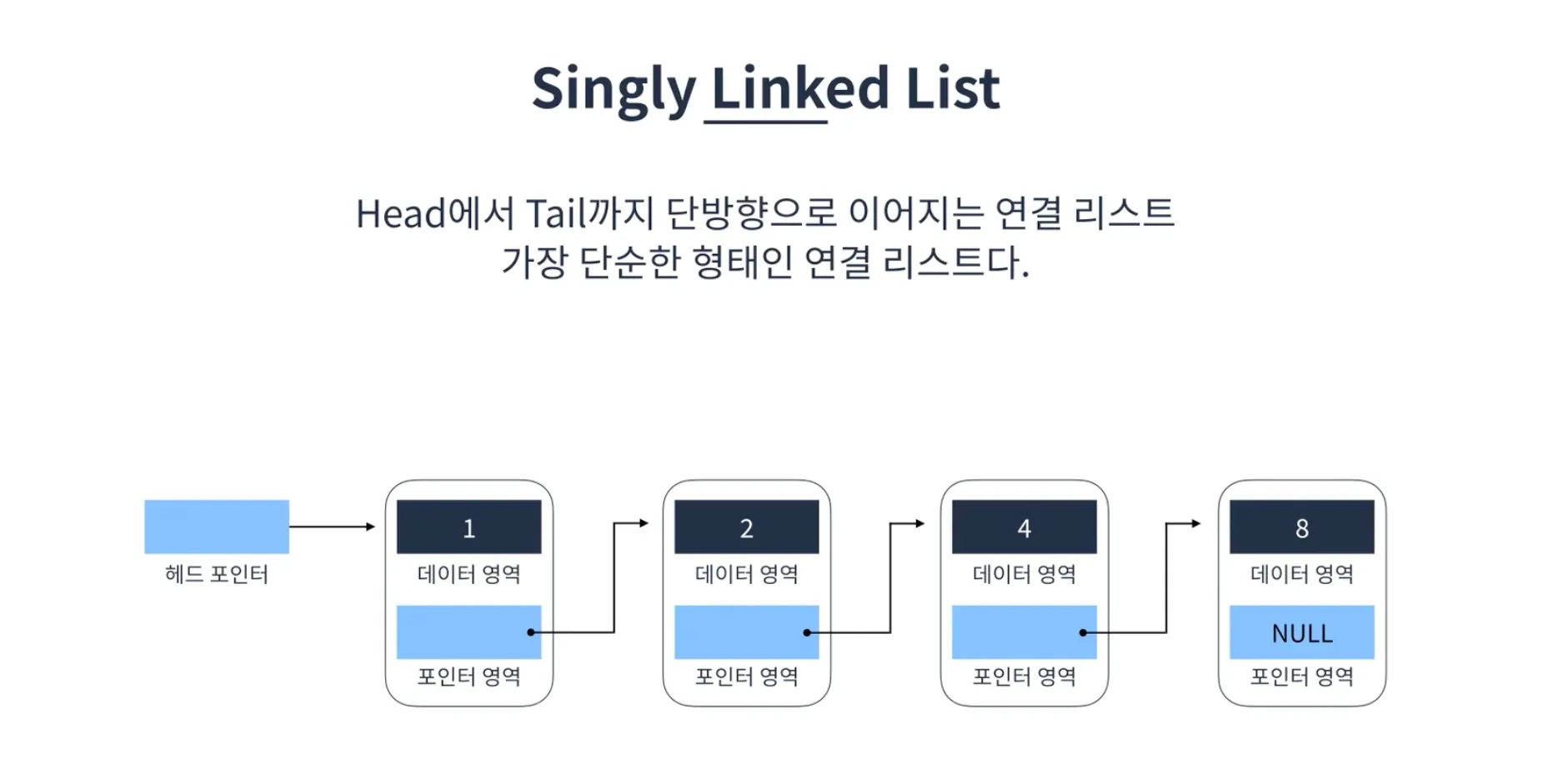
연결리스트는 메모리가 허용하는 한 요소를 제한없이 추가할 수 있다. 탐색에는 선형시간이 소요되지만 요소를 추가하거나 제거할 때는 상수시간이 소요된다. 이러한 점에서 배열과 장단점이 반대된다고 할 수 있다. 연결리스트에는 단일 연결리스트(Singly Linked List), 이중 연결리스트(Doubly Linked List), 선형 연결리스트(Circular Linked List)가 존재한다.

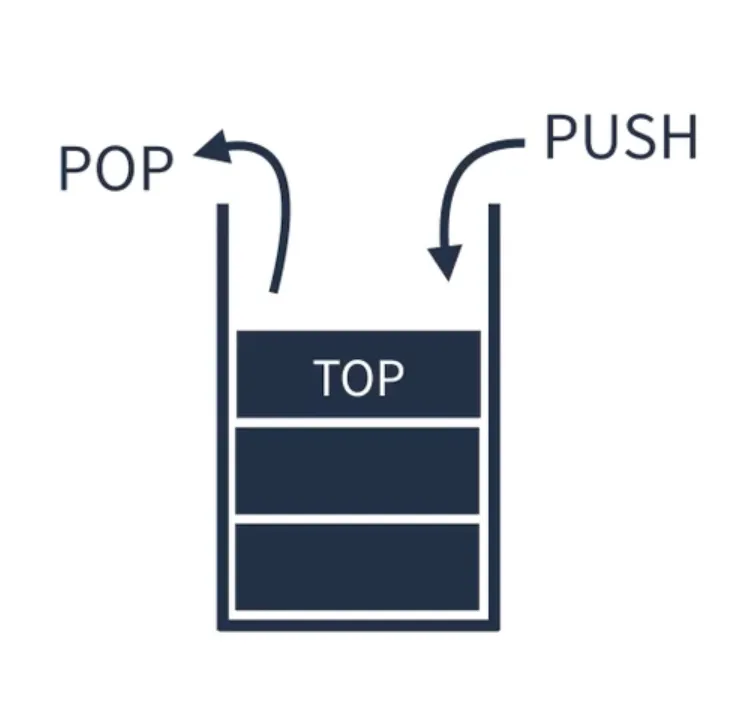
스택
스택(Stack)은 Last In First Out(LIFO, 후입선출)이라는 개념을 가진 선형 자료구조이다. 스택은 밑부분이 막혀있는 상자를 생각하면 된다. 스택에 새로운 데이터를 추가하는 것을 PUSH라고 하며 이 경우 현재 데이터들 위에 새로운 데이터가 쌓이게 된다. 스택에서 데이터를 삭제하는 것을 POP이라고 하고 이 경우 현재 데이터들 중 TOP에 위치한 데이터가 삭제된다. 스택은 웹 브라우저 방문기록(뒤로가기 할 때 사용)이나 실행취소(ctrl+z) 등에서 사용한다.
큐
큐(Queue)는 First In First Out(FIFO, 선입선출)이라는 개념을 가진 선형 자료구조이다. 큐에는 Linear Queue와 Circular Queue가 존재한다.
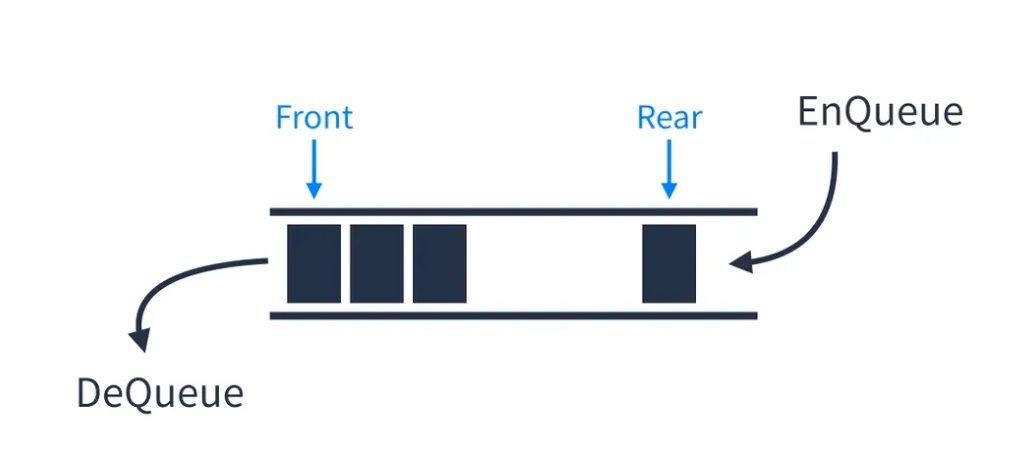
큐는 놀이공원에서 사람들이 놀이기구를 타려고 서있는 줄에 빗대어 생각하면 된다. 본인 차례가 되어 놀이기구를 타러 가는 사람을 DeQueue, 이제 줄을 서는 사람을 EnQueue, 줄의 맨 앞에 서 있는 사람을 Front, 맨 뒤에 서 있는 사람을 Rear라고 생각하면 된다.
큐와 비슷한 개념으로는 ‘덱(Deque)’이 있다. 이는 double-ended queue를 줄여서 표현한 것으로, 앞으로도 뒤로도 넣을 수 있고 앞으로도 뒤로도 뺄 수 있는 자료구조이다. 덱은 큐와 스택의 특성을 모두 갖는 자료구조로 이해되고 있다.
해시 테이블
해시 테이블(Hash Table)은 키를 해싱하여 나온 index에 값을 저장하는 선형 자료구조이다. 삽입은 O(1)이며 키를 알고 있다면 삭제, 탐색도 O(1)로 수행한다. 해시 테이블의 인덱스는 버켓(Bucket)이라고 한다. 학교 사물함과 같은 구조라고 보면 된다.
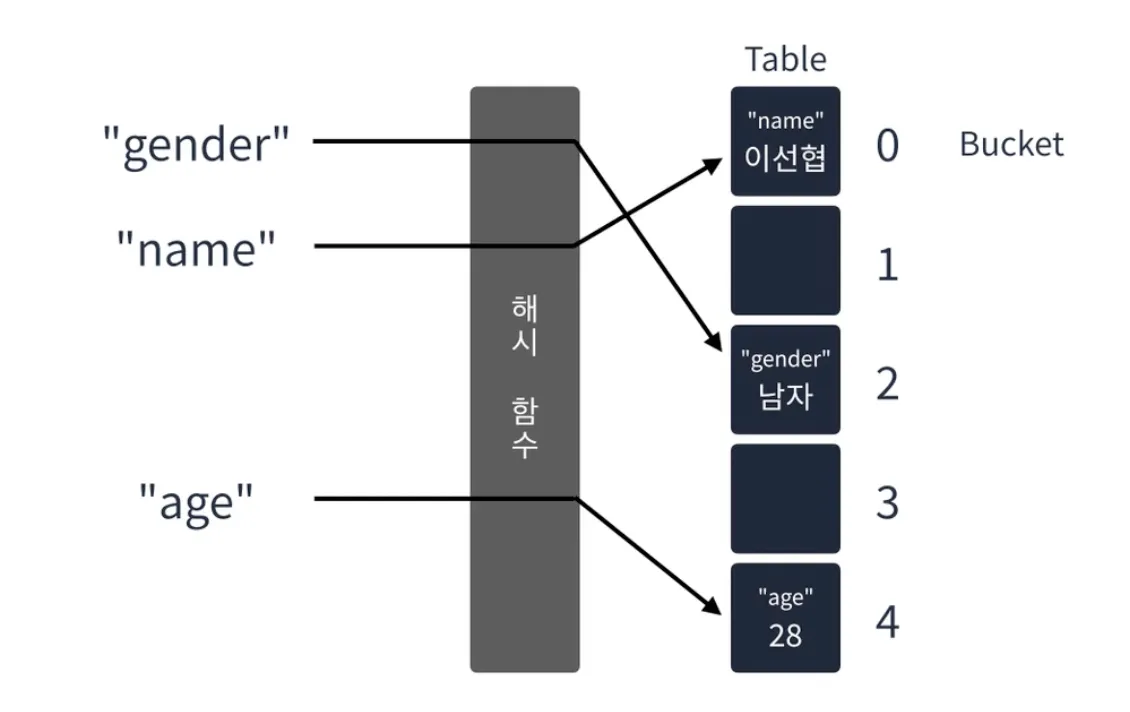
여기서 해시 함수는 입력받은 값을 특정 범위 내의 숫자로 변경하는 함수이다. 예를들어 이름의 아스키코드의 합 등으로 변환할 수 있다. 그러나 이 해시 함수의 결과값이 겹친다면 해시 충돌(Hash Collision)이 일어나게 된다. 이러한 해시 충돌을 막기 위한 방법이 여러가지 있다.
▶️ 선형 탐사법은 충돌이 발생하면 해당 값을 한 칸 옆으로 이동한다. 만약 한 칸 옆에서 또 충돌이 발생할 경우 다시 한 칸 옆으로 이동한다. 최악의 경우 선형시간이 소요된다.
▶️ 제곱 탐사법은 선형 탐사법을 이용할 경우 특정 영역에 데이터가 몰릴 수 있으므로 이를 보완한 방법이다. 제곱 탐사법은 충돌 횟수의 제곱만큼 데이터를 옆으로 이동시킨다.
▶️ 이중 해싱은 충돌이 발생하면 두번째 해시 함수를 이용하여 새로운 인덱스를 만들어내는 방법이다.
▶️ 분리 연결법은 버켓의 값을 연결리스트로 사용하여 충돌이 발생하면 리스트에 값을 추가한다.
그래프
그래프는 정점(Node)과 정점(Node) 사이를 연결하는 간선(Edge)으로 이루어진 비선형 자료구조이다. 지하철 노선도를 생각하면 된다.
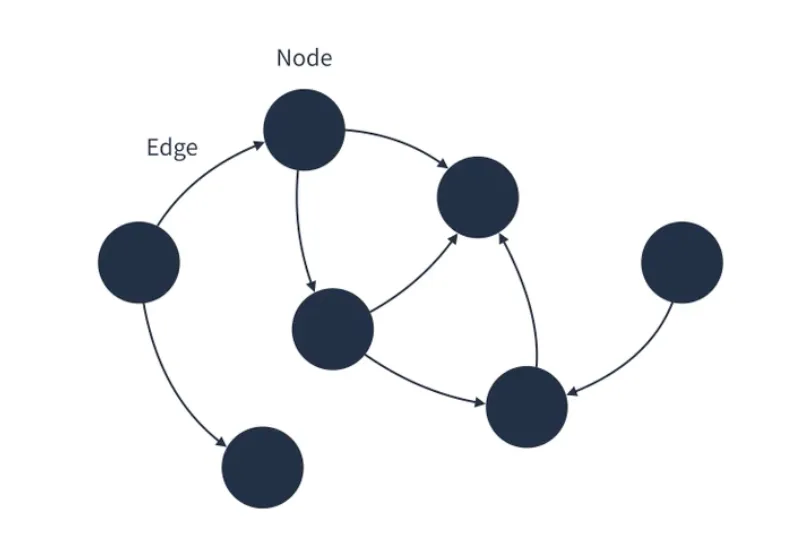
▶️ 그래프의 특징
▶️ 그래프의 분류
트리
트리는 방향 그래프의 일종으로 정점(Node)을 가리키는 간선(Edge)이 하나 밖에 없는 구조를 가지고 있다. 조직도를 생각하면 된다.
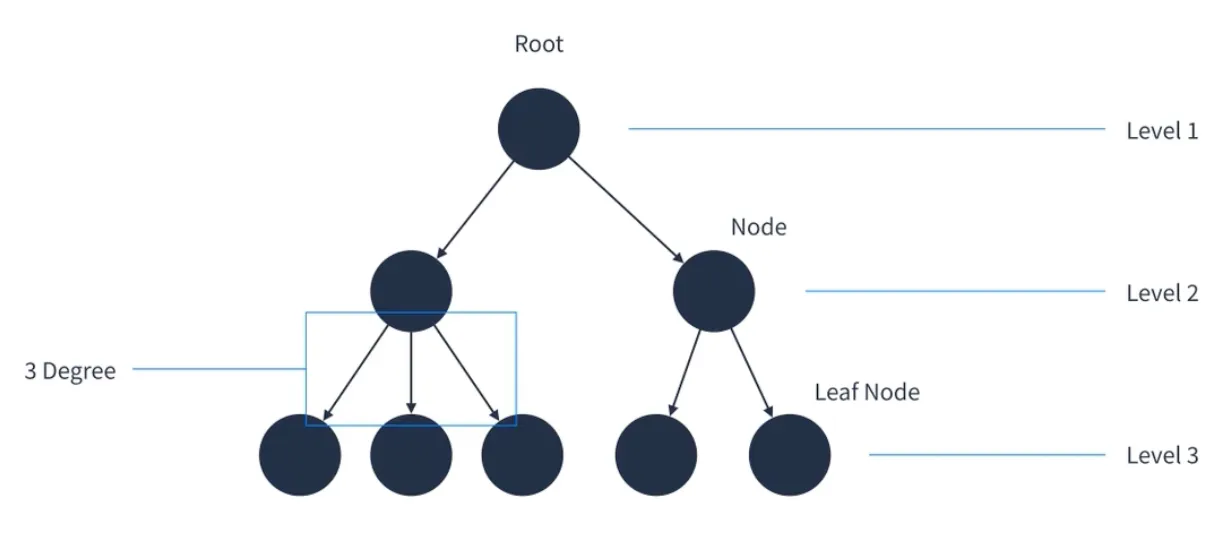
▶️ 트리의 특징
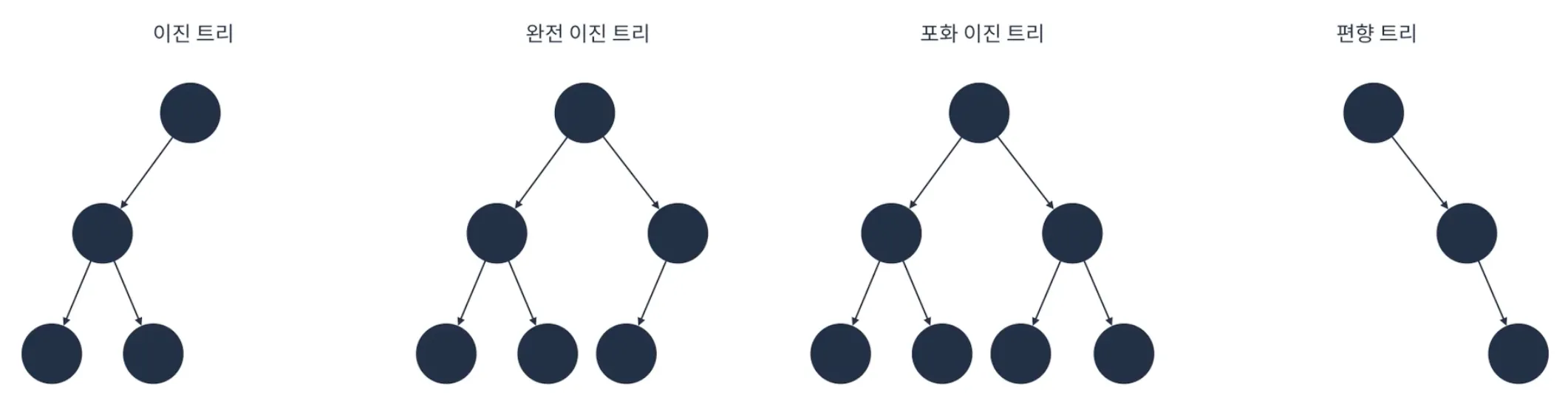
▶️ 이진트리
이진 트리는 각 정점이 최대 2개의 자식을 가지는 트리를 말한다.