MySQL
🪤 DBMS (Database Management System)
SQL (Structured Query Language)
관계형 (SQL, RDBMS)
비관계형 (NoSQL, Non RDBMS)
🛹 SELECT
기본 문법
필요한 값을 임의로 추가
WHERE
ORDER BY
LIMIT
AS
JOIN
🏉 정규화
제 1 정규형
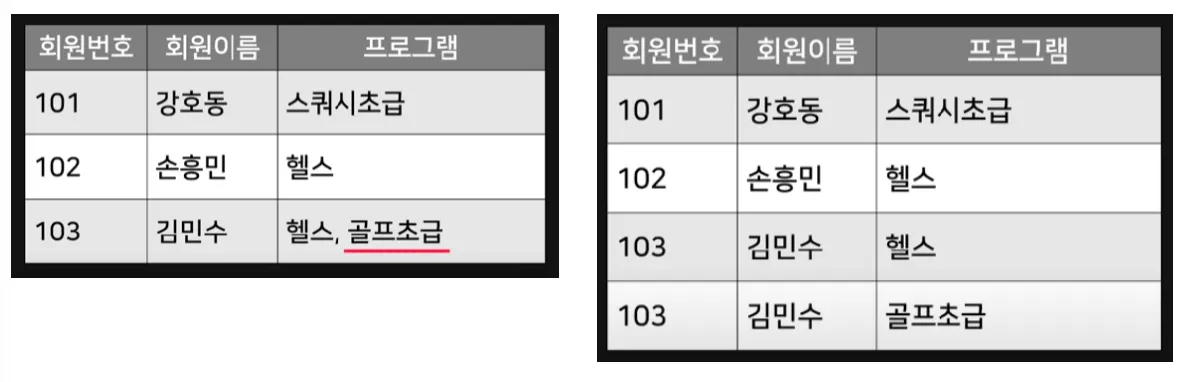
제 2 정규형
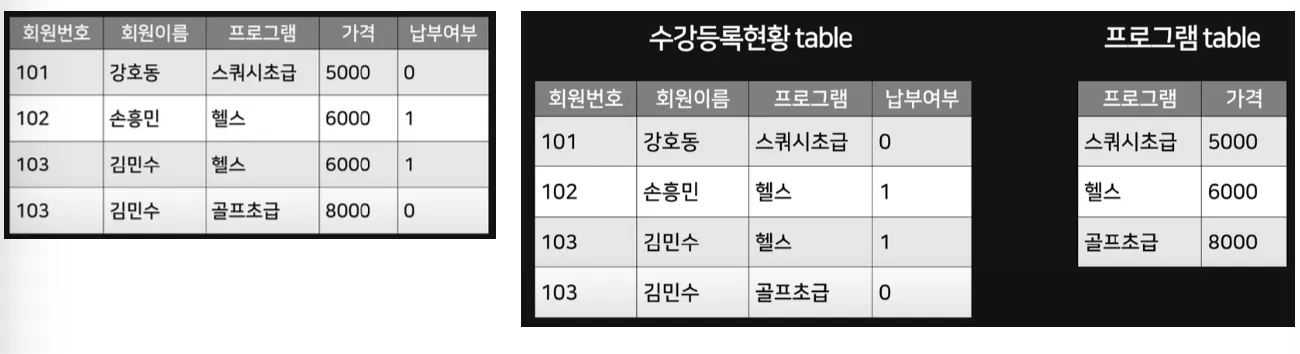
제 3 정규형
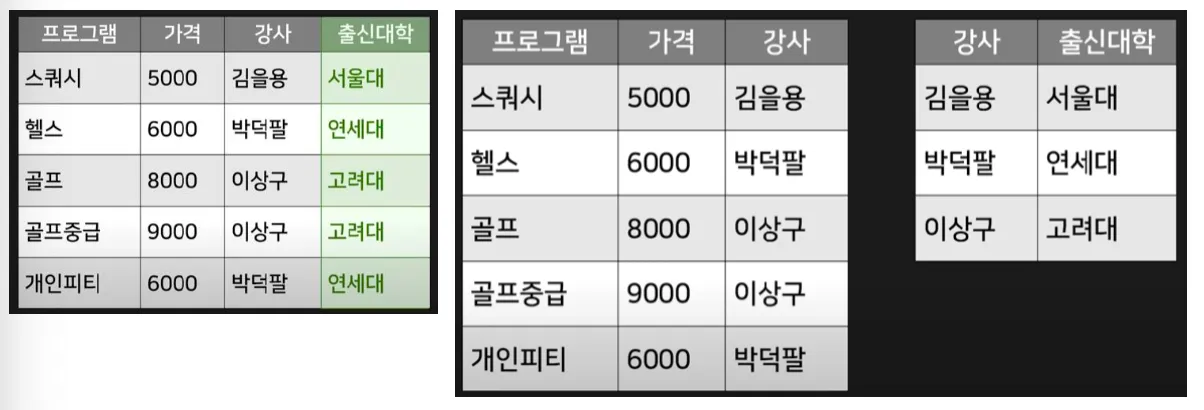
외래 키 (Foreign Key)
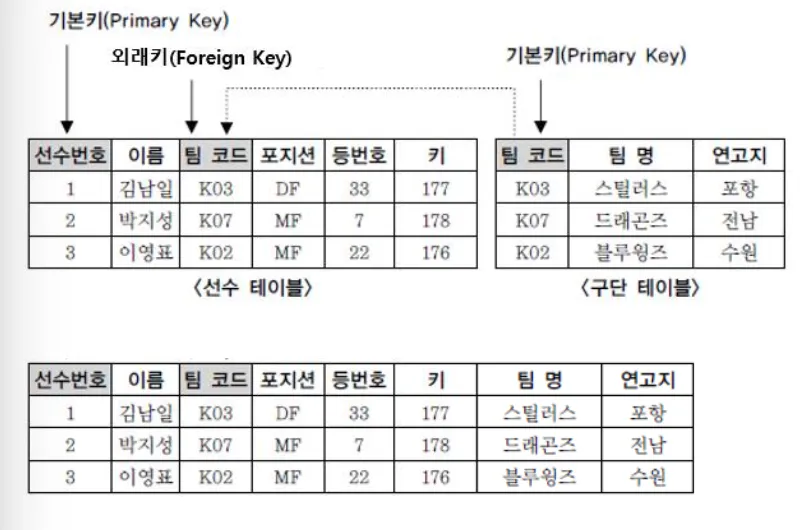
🪀 DB 만들기
DB 생성
TABLE 생성
CREATE TABLE user (`ID_PK` INT NOT NULL PRIMARY KEY AUTO_INCREMENT,`NAME` VARCHAR(100) NOT NULL,`EMAIL` VARCHAR(100) UNIQUE NOT NULL,`PASSWORD` VARCHAR(100) NOT NULL,`ADDRESS` VARCHAR(100) NOT NULL,`AGE` TINYINT UNSIGNED,`MEMBERSHIP` TINYINT DEFAULT 0,`REGISTER_TIME` DATETIME DEFAULT CURRENT_TIMESTAMP,`UPDATE_TIME` DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP);
DATA 삽입
INSERT INTO user (NAME, EMAIL, PASSWORD, ADDRESS, AGE)VALUES ('장경은', 'j56237@naver.com', '1234', '서울 영등포구', '27');
DATA 수정 및 삭제
DELETE FROM user WHERE ID_PK = 3;
UPDATE user SET AGE = AGE + 1 WHERE ID_PK = 1;
ALTER TABLE test_table CHANGE COLUMN NAME EMAIL VARCHAR(100);
→ test_table의 NAME 컬럼을 EMAIL(VARCHAR100)로 변경
ALTER TABLE test_table ADD COLUMN ADDRESS VARCHAR(100) AFTER EMAIL;
→ ADDRESS 컬럼 추가
ALTER TABLE test_table DROP ADDRESS;
→ ADDRESS 컬럼 삭제