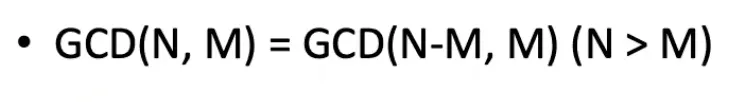2022년 2학기 수업
Chapter 1, 2. 알고리즘 개요
알고리즘이란?
알고리즘이라는 용어는 9세기 페르시아 수학자 알콰리즈미의 이름에서 유래되었다. 알고리즘은 특정한 문제가 있을 때 이를 효율적이고 빠르게 해결하는 방법을 말한다. 상황에 따라 적절한 알고리즘을 활용하는 것이 프로그래머의 역량이다.
여러가지 알고리즘
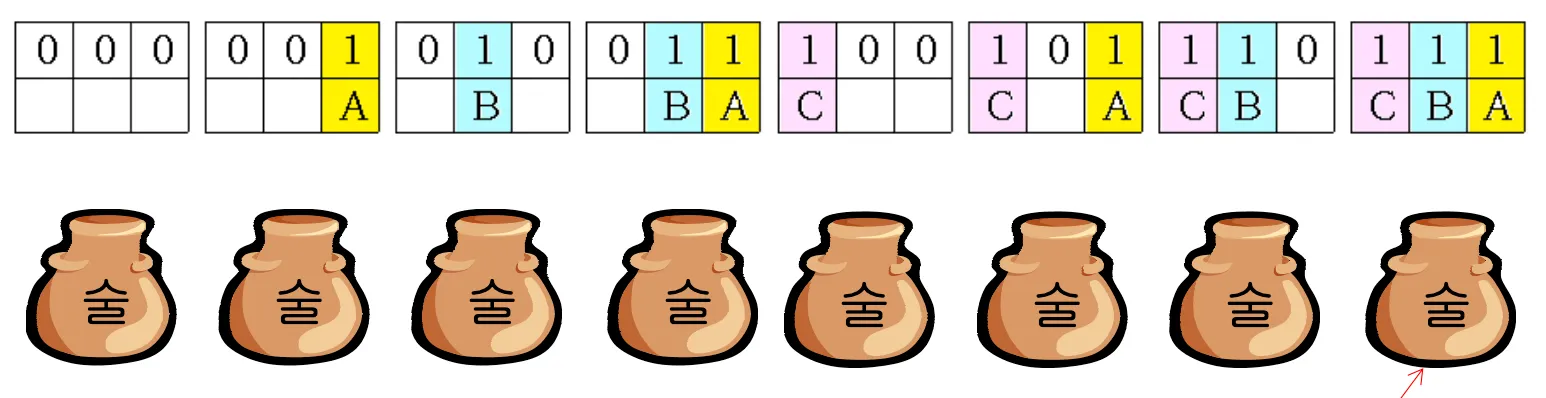
순차탐색 (Sequential Search) : 카드를 한 장씩 차례대로 읽어가며 찾는 방법.완전탐색 (Brute-Force Search) : 가능한 모든 경우를 다 탐색해보는 방법.이진탐색 (Binary Search) : 오름차순 또는 내림차순으로 정렬된 데이터를 반으로 나누고, 나누어진 반을 다시 반으로 나누는 과정을 반복하여 원하는 데이터를 찾는 방법.동전 거스름돈 문제 (Change of Coin) : 남은 거스름돈 액수를 넘지 않는 한도에서 가장 큰 액면의 동전을 계속하여 선택하는 것 - 그리디(Greedy) 알고리즘 한붓그리기 문제 (Euler Trail) : 현재 점으로부터 진행하고자 하는 점을 지나서 현재 점으로 돌아오는 사이클을 찾는 것. (사이클이 존재하는 노드로 진행하면 됨)미로 찾기 문제 (Escape a Maze) : 현 위치에서 한 방향을 선택하고, 벽에 오른손을 댄다. 그리고 출구가 나올 때까지 계속 오른손을 벽에서 떼지 않고 걸어간다.가짜 동전 찾기 (Find a Fake Coins) (3번이 가장 효율적인 알고리즘)임의의 동전 1개를 저울 왼편에 올리고, 나머지 동전을 하나씩 오른편에 올려서 찾는다. → 1 ~ (n-1), 완전탐색・순차탐색동전을 2개씩 짝을 지어, n/2 짝을 각각 저울에 달아서 가짜 동전을 찾는다. → K=n/2, 1~(K-1)동전 더미를 반으로 나누어 저울에 달고, 가벼운 쪽의 더미를 계속 반으로 나누어 저울에 단다. 분할된 더미의 동전 수가 1개씩이면, 마지막으로 저울을 달아 가벼운 쪽의 동전이 가짜임을 찾아낸다. → 1/2^x N = 2, x = log N -1, 이진탐색독이 든 술단지 (Find a Poisoned Drink)4개의 술단지가 있을 때, 술단지에 2진수를 이용하여 신하가 술을 맛보면 1, 안 보면 0으로 한다.
이 경우 아무도 죽지 않으면 00 술단지, 신하1이 죽으면 01술단지, 신하2가 죽으면 10술단지, 둘 다 죽으면 11술단지에 독이 있게 된다.
8개의 술단지가 있을 때는
이런식으로 된다. (0~ log N)
알고리즘의 특성
정확성(Correctness) : 알고리즘은 주어진 입력에 대해 올바른 해를 주어야 한다.수행성(Runnability) : 알고리즘의 각 단계는 컴퓨터에서 수행이 가능하여야 한다.유한성(Finiteness) : 알고리즘은 유한 시간 내에 종료되어야 한다.효율성(Efficiency) : 알고리즘은 효율적일수록 그 가치가 높아진다.최초의 알고리즘
유클리드(Euclid)의 최대공약수를 찾는 알고리즘이 가장 오래된 알고리즘이다. 최대공약수는 2개 이상의 자연수의 공약수들 중에서 가장 큰 수. 해당 알고리즘은 아래와 같다.
Ex)
최대공약수 (24, 14)
= 최대공약수 (10, 14)
= 최대공약수 (4, 10)
= 최대공약수 (6, 4)
= 최대공약수 (2, 4)
= 최대공약수 (2, 2)
= 최대공약수 (2, 0) ⇒ 24와 14의 최대공약수는 2이다.
알고리즘의 표현 방법
보통 말(Natural Langauge)로 표현첫 카드의 숫자를 읽고 기억해 둔다.다음 카드의 숫자를 읽고, 그 숫자를 머리속 숫자와 비교한다.비교 후 큰 숫자를 머릿속에 기억한다.다음에 읽을 카드가 남아 있으면 line2로 간다.머릿속에 기억된 숫자가 최대 숫자이다.의사 코드(Pseudo Code)로 표현max = A[0]for i = 1 to 9if(A[i] > max) max = A[i]return max플로차트(flow chart)로 표현► 마름모 ⇒ 비교 / 평행사변형 ⇒ 출력 / 직사각형 ⇒ 대입
알고리즘의 분류
알고리즘은 문제의 해결 방식에 따라 크게 다음과 같이 분류된다.
분할 정복 알고리즘그리디 알고리즘동적 계획 알고리즘근사 알고리즘백트래킹 기법분기 한정 기법그 외에도 다른 알고리즘이 있다.
알고리즘의 효율성 표현
알고리즘의 효율성은 수행시간(시간복잡도)이나 사용되는 메모리 공간의 크기(공간복잡도)로 나타낼 수 있다. 알고리즘의 복잡도를 표현하는 데는 다음과 같은 분석 방법들이 있다.
최악 경우 분석평균 경우 분석최선 경우 분석복잡도의 점근적 표기
점근적 표기 방법에는 다음과 같은 것들이 있다.
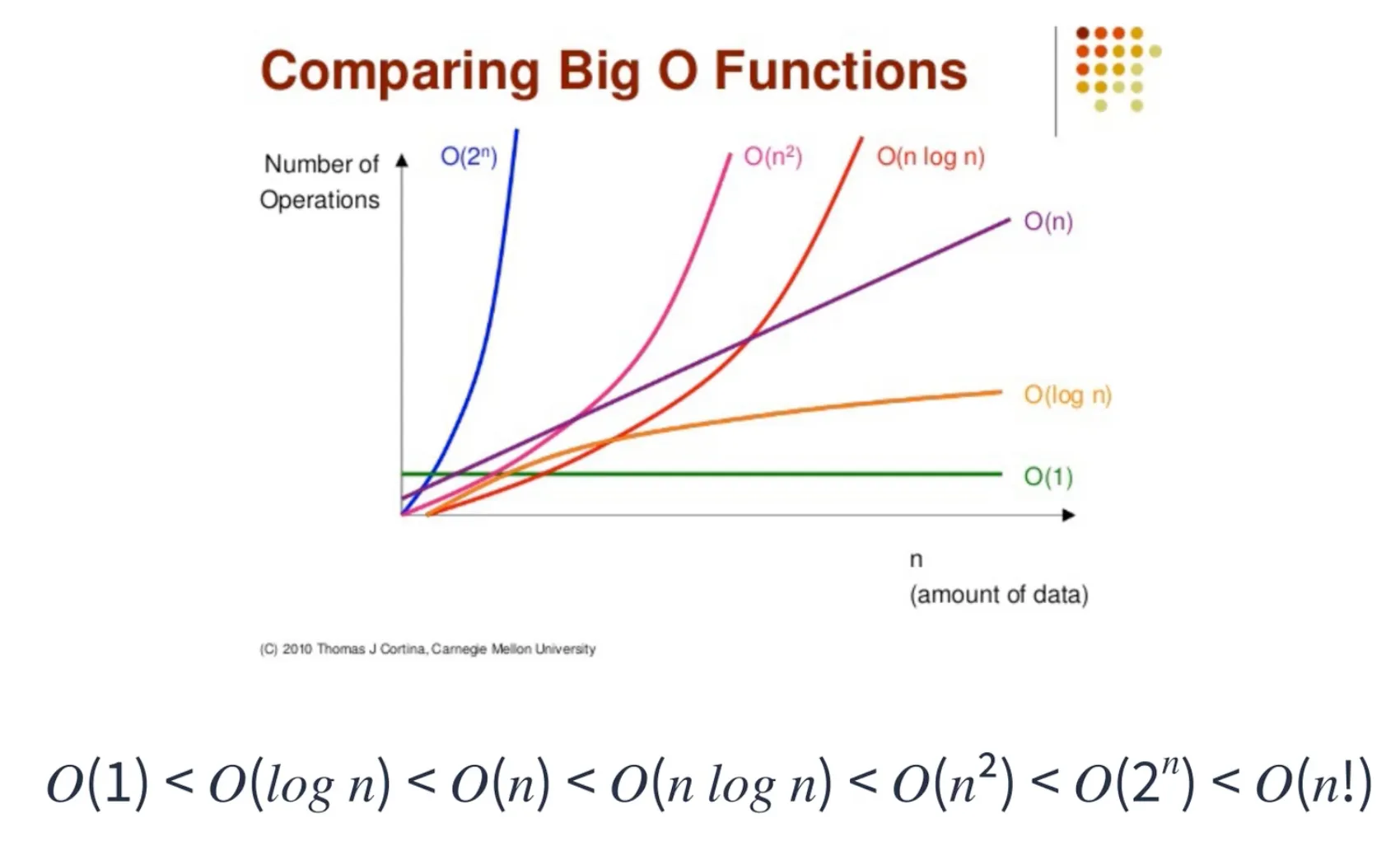
O(Big O) 표기 → 점근적 상한Ω(Big Omega) 표기 → 점근적 하한θ(Theta) 표기 → 상한과 하한이 동시에 적용되는 경우 (O와 Omega가 동일할 경우 사용이들 중 Big O 표기법은 가장 많이 사용되는 점근적 표기의 하나이다. 이를 통해 알고리즘이 얼마나 효율적인지 알 수 있다.
그래프의 시간 복잡도의 효율성은 가장 왼쪽의 O(1)가 가장 좋으며 가장 오른쪽의 O(n!)이 가장 떨어진다. 차례대로 상수시간(constant time), 로그시간(logarithmic time), 선형시간(linear time), 선형로그시간(log-linear time), 2차시간(quadratic time), 3차시간(cubic time), 다항식 시간(n^k, k는 상수, polynomial time), 지수시간(exponential time), 팩토리얼시간이라고 한다.
빅오 표기법의 큰 특징은 두가지가 있다.
첫번째는 상수항은 무시한다는 것이다. 상수시간은 O(1)로 표기한다. 예시는 아래와 같다.
O(2N) → O(N)O(2) → O(1)두번째는 가장 큰 항 외엔 무시한다는 것이다. 예시는 아래와 같다.
O(N^2 + 2N + 1) → O(N^2)☑️ 연습문제
☑️ 참고 :
Chapter 3. 분할 정복 알고리즘
분할 정복(Divde-and-Conquer) 알고리즘이란 주어진 문제의 입력을 분할하여 문제를 해결(정복)하는 방식의 알고리즘이다. 분할된 입력에 대하여 동일한 알고리즘을 적용하여 해를 계산하며, 이들의 해를 취합하여 원래 문제의 해를 얻는다.
3.1 합병 정렬 (Merge Sort)
합병 정렬은 입력이 2개의 부분문제로 분할되고, 부분문제의 크기가 1/2로 감소하는 분할 정복 알고리즘이다. 데이터를 더이상 나눌 수 없을 때까지 분할하고, 합병하는 과정에서 정렬한다. 아래 그림과 같다.